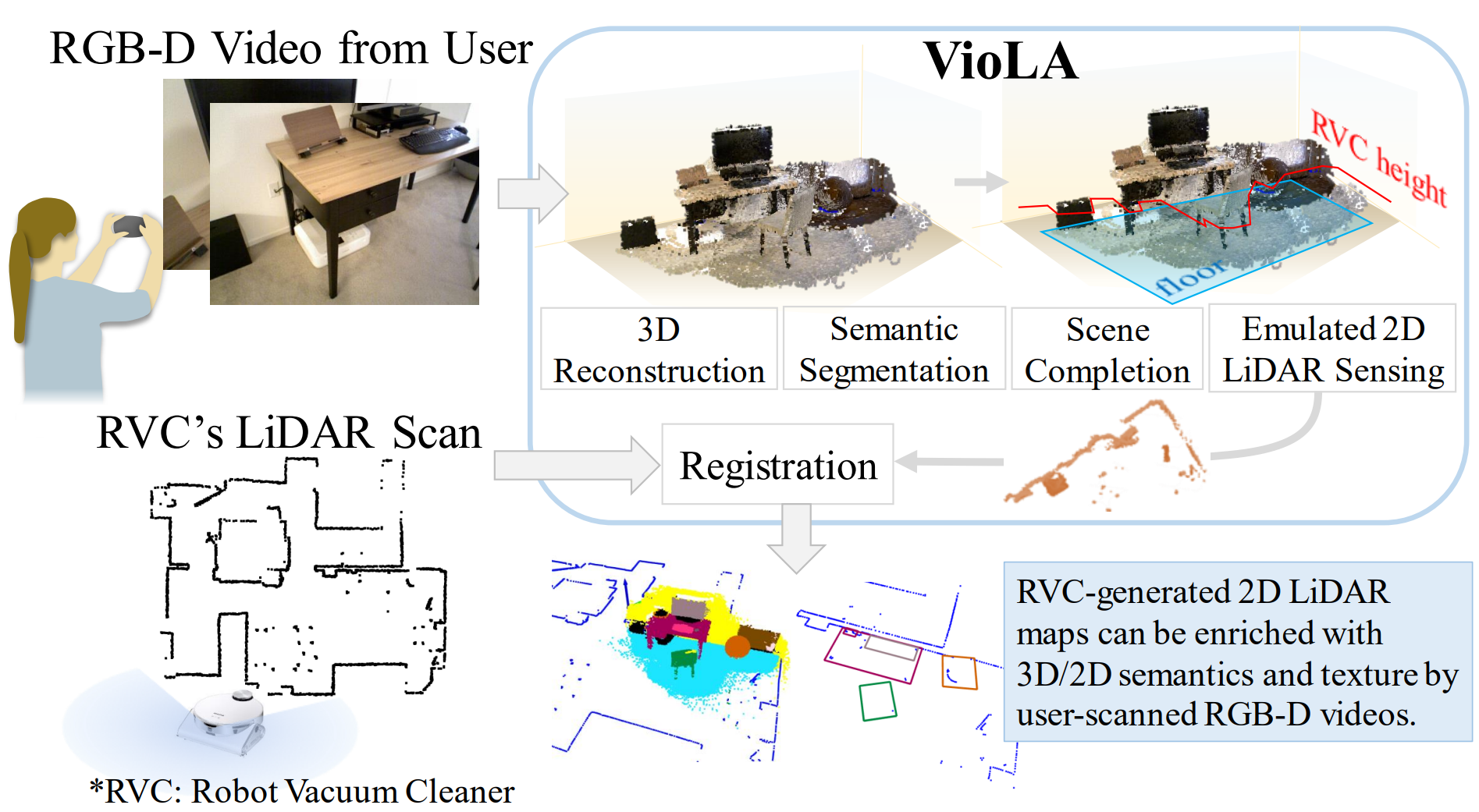
We found that reconstructed points at the height of the LiDAR scan are critical for registration success.
However, these points might be missing due to the video not capturing the lower part of the scene or the SLAM
algorithm suffering from matching featureless points. To provide this missing information, we proposed a
strategy for selecting virtual
viewpoints and a scene completion module that performs inpainting and 3D lifting from the chosen viewpoints.
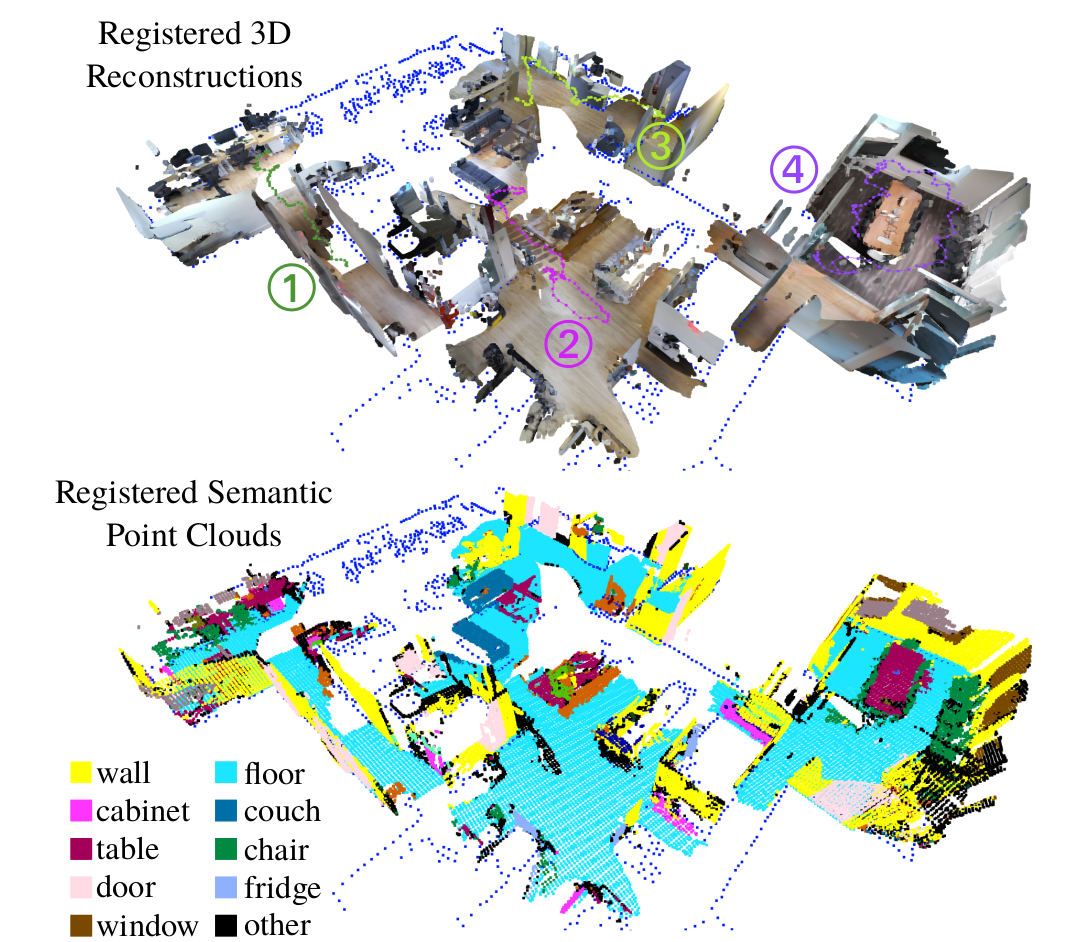
We evaluated VioLA on two real-world RGB-D benchmarks, as well as a self-captured dataset of
a large office scene. Notably, our proposed scene completion module improves the pose registration performance
by up to 20%.
In the animations below, we show 1) the reconstruction from an RGB-D image sequence taken from the Redwood
dataset,
2) completed point cloud using VioLA's scene completion module that grounds the floor to estimated floor
surface, and 3)
scene completion without floor grounding.