Realistic one-shot mesh-based head avatars
Abstract
We present a system for the creation of realistic one-shot mesh-based (ROME) human head avatars. From a single photograph, our system estimates the head mesh (with person-specific details in both the facial and non-facial head parts) as well as the neural texture encoding, local photometric and geometric details. The resulting avatars are rigged and can be rendered using a deep rendering network, which is trained alongside the mesh and texture estimators on a dataset of in-the-wild videos. In the experiments, we observe that our system performs competitively both in terms of head geometry recovery and the quality of renders, especially for cross-person reenactment.
Main idea
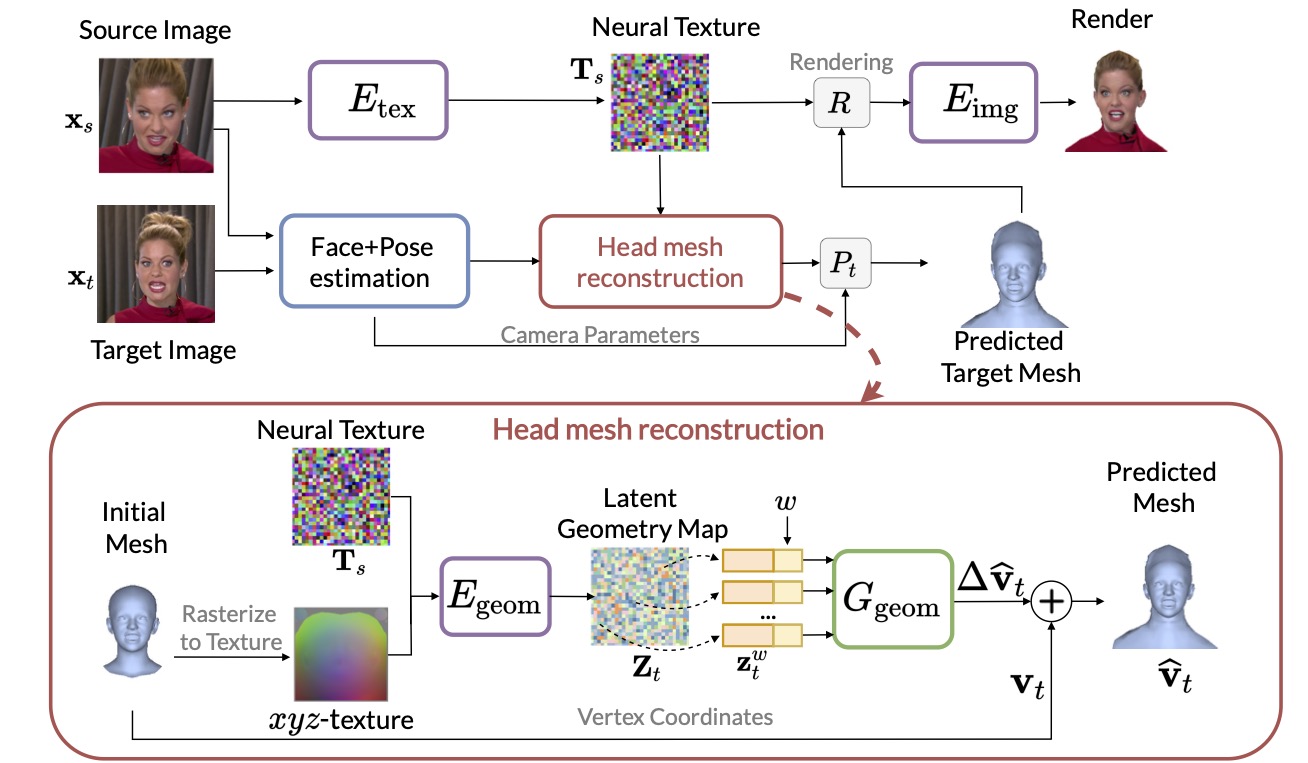
We use a neural texture map to represent both the geometry and appearance. This texture is estimated from a single source image by a texture encoder. Also, we estimate facial blendshape parameters, and the camera parameters from both the source and the driving images using a pre-trained system for facial reconstruction (e.g. DECA).
Both the neural texture and the head mesh are fed into our head reconstruction pipeline, which predicts displacements to the input head mesh. We use a combination of a geometry autoencoding network that produces latent geometry features, and a local geometry decoding MLP to predict displacements. These displacements reconstruct the geometry, such as hair and shoulders.
The reconstructed mesh is then used for neural rendering to produce photo-realistic images. We use a standard deferred neural rendering pipeline, which renders a neural texture instead of a regular RGB texture, and decodes it into the image via an image-to-image network.
Video Comparision
Self-reenactment
Cross-reenactment
Distilation Results
Here we show how to integrate our distilled linear model with existing parametric models.

BibTeX
@inproceedings{Khakhulin2022ROME,
author = {Khakhulin, Taras and Sklyarova, Vanessa and Lempitsky, Victor and Zakharov, Egor}
title = {Realistic One-shot Mesh-based Head Avatars},
booktitle = {European Conference of Computer vision (ECCV)},
year = {2022}
}