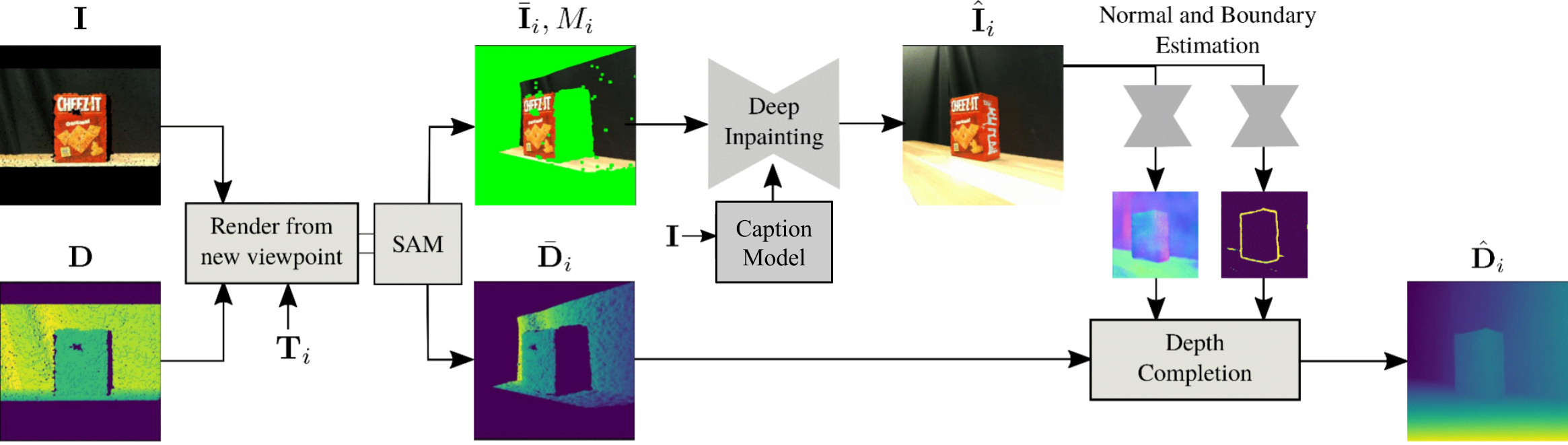
We introduce Rotate-Inpaint-Complete (RIC), a method for scene reconstruction that works by structurally breaking the problem into two steps: rendering novel views via inpainting and 2D to 3D scene lifting. Specifically, we leverage the generalization capability of large visual language models (Dalle-2) to inpaint the missing areas of scene color images rendered from different views. Next, we lift these inpainted images to 3D by predicting normals of the inpainted image and solving for the missing depth values. By predicting for normals instead of depth directly, our method allows for robustness to changes in depth distributions and scale.
We show that our method outperforms multiple baselines while providing generalization to novel objects and scenes. With rigourous quantitative evaluation on novel scenes with muliple unknown objects with many instances of heavy occlusion, we show our methods ability to reconstruct both geometry and texture in a realistic manner.
Above we show qualitative results of our method on the
HOPE
dataset. We also release the code to demonstrate the usefulness of our approach and allow for further research in field of scene reconstruction.