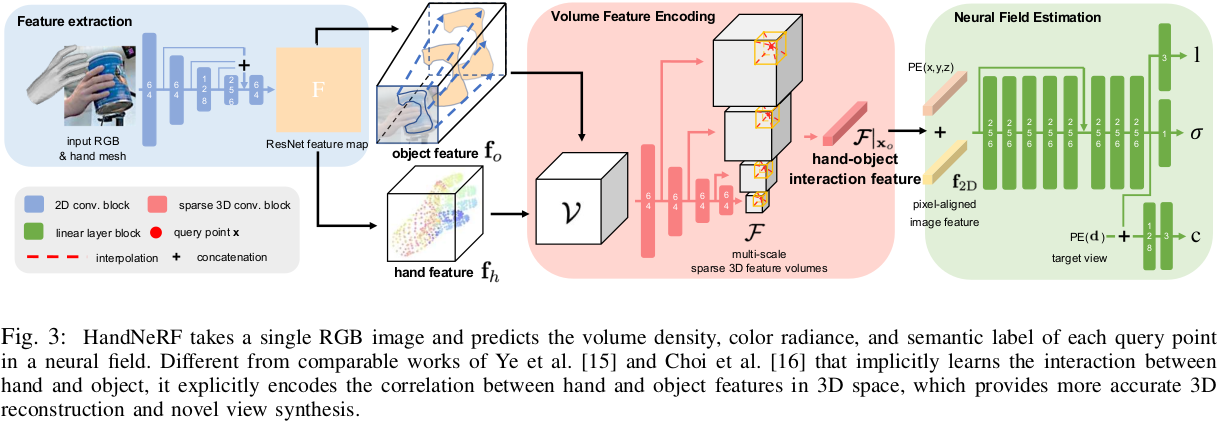
Given a single RGB image of a hand-object interaction scene, HandNeRF predicts the hand and object’s density, color, and
semantics, which can be converted to reconstruction of 3D hand and object meshes and rendered to novel view images (RGB,
depth, and semantic segmentation).
HandNeRF learns the correlation between hand and object geometry from different types
of hand-object interactions, supervised by sparse view images. HandNeRF is tested on a novel scene with an unseen
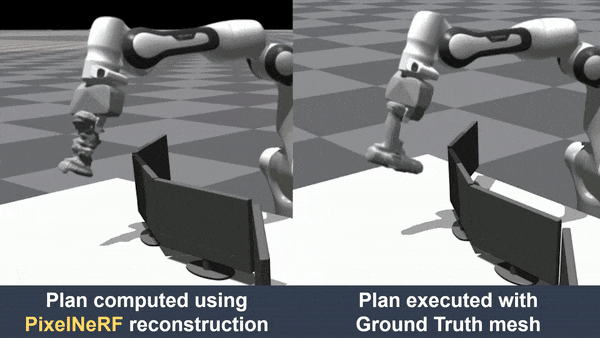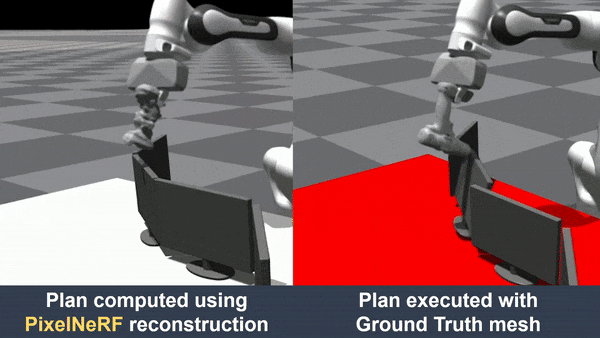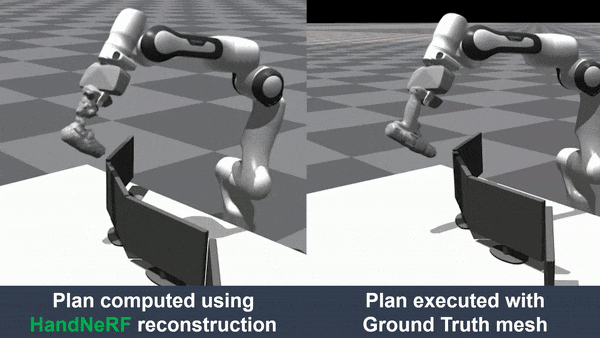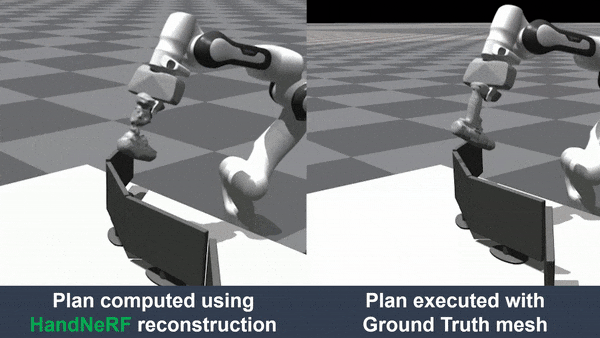
hand-object interaction. We further demonstrated that object reconstruction from HandNeRF ensures more accurate
execution of downstream tasks, such as grasping and motion planning for robotic hand-over and manipulation.
Why do we use weak-supervision from sparse-view 2D images?
Acquiring precise 3D object annotations from hand-object interaction scenes is challenging and labor-intensive, not to
mention creating 3D CAD models for each object. Also, since the 3D ground truth itself contains sufficient information
about hand-object interactions, it can readily supervise models regarding interaction priors, such as using contact
information. Instead, we compare models utilizing weak-supervision from easily-obtained, cost-effective sparse-view
images rather than 3D ground truth, to assess the efficacy of different approaches for encoding hand-object interaction
correlations.